import os
import sys
import csv
import dspy
import langwatch
from dotenv import load_dotenv
from dspy.evaluate import Evaluate
from datasets import load_dataset
import pandas as pd
# Automatically add the project root to sys.path
project_root = os.path.abspath(os.path.join(os.getcwd(), '..', '..'))
if project_root not in sys.path:
sys.path.insert(0, project_root)
# Keys are kept in .env file
load_dotenv()Observe DSPy’s CORPO Optimizer with LangWatch - Tutorial
This tutorial explains DSPy’s COPRO prompt optimizer and how to use LangWatch to observe its internal processes. This tutorial targets DSPy beginners, providing an introduciton to how DSPy optimizers work using clear step by step setup instructions.
Background
When first using DSPy optimizers, it’s common to feel uncertain about their internal operations, effectiveness, configuration choices, LLM call volumes, etc.
When I started with DSPy I was always concerned I was doing something wrong that would just waste money on LLM calls and miss out on getting better results.
For me, I wanted to examine the optimizers in depth to fully understand how they work, leading me to seek observation tools that could trace their execution. I settled on LangWatch, a logging and dashboard tool; but its integration with DSPy was also non-trivial to set up for full visibility.
In this tutorial I walk through details of using DSPy COPRO Optimizer and LangWatch and hopefully this can help you accelerate using both.
Key Concepts
DSPY COPRO optimizer is a basic prompt optimizer. It serves as an entry point to DSPy optimizers.
LangWatch is an open-source tool for Prompt and Agent observation; it is installable locally. You can get LangWatch for local installation here.
Tutorial Steps Overview
- Create a prompt with DSPy that scores data.
- Load a dataset we will use to evaluate and optimize the prompt.
- Run a baseline evaluation of the prompt using the cheapest LLM model.
- Run the COPRO optimizer on the prompt.
- Evaluate the optimized prompt.
- Along the way log all DSPy actions above to LangWatch to inspect COPRO’s operations, including prompts, iterations, and costs.
COPRO augments prompts only, keeping setup simple to focus on connecting DSPy with LangWatch and observing DSPy’s processes.
This tutorial uses Python and assumes you can install libraries or get a code agent to do it for you.
Python Imports
Lets start with imports we need, nothing special here except some pathing for jupter on my Windoze machine.
DSPy Signature and Module, and Metric
First we need a DSPy managed prompt. This is what we will optimize.
This code declares our DSPy Signature and Module classes. If you are not familiar with these then go first read the basics on using DSPy Singnatures and Modules.
The Singature here asks the LLM to evaluate if a given sentence is grammatically correct or not.
This code also sets up a metric, which is how we score the LLM’s response to our prompt. The metric simply comparies the LLM response (0,1) to the known correct answer label.
# Define signature
class GrammaticalitySignature(dspy.Signature):
"""Classify if the sentence is grammatically correct (1) or not (0).""" #<-- this is the prompt we will optimize
sentence = dspy.InputField()
label = dspy.OutputField(desc="1 if correct, 0 if incorrect")
# Define module
class GrammaticalityClassifier(dspy.Module):
def __init__(self):
super().__init__()
self.predict = dspy.Predict(GrammaticalitySignature)
def forward(self, sentence):
return self.predict(sentence=sentence)
# Define validation metric - evaluate if a LLM model predicts the grammar score (correct grammar or not) accurately.
def custom_metric(example, pred, trace=None):
return example.label == pred.labelTraining Dataset Setup
Next we need some data.
Training requires data and I wanted this tutorial to use a dataset you can just fetch and not have to generate or collect. Luckily I found this obscure example from Maylad31 on Github which I borrowed from for the foundation for this tutorial.
The CoLA Grammar Dataset
The dataset used here is the CoLA grammar training set. It is a set of correct and incorrect grammar examples with labels for the correctness (0, 1).
Its rows look like this, Label indicates if the sentence is grammatically correct or not:
| Sentence | Label |
|---|---|
| The book what inspired them was very long. | 0 |
| This flyer and that flyer differ apart. | 0 |
| Anson believed himself to be handsome. | 1 |
| John is sad. | 1 |
Prepare the Dataset for Evaluating and Training our Prompt
The code below will fetch it for free directly from HuggingFace and prepare it for our uses.
# Load CoLA dataset (Corpus of Linguistic Acceptability)
# Source https://huggingface.co/datasets/linxinyuan/cola/tree/main
dataset = load_dataset("glue", "cola")
train_df = dataset['train'].to_pandas()
val_df = dataset['validation'].to_pandas()
# Shuffle and truncate a subset of the training split for demonstration
train_df = train_df.sample(frac=1, random_state=23).head(10).reset_index(drop=True)
# Shuffle and truncate a subset of the test split for demonstration
val_df = val_df.sample(frac=1, random_state=23).head(300).reset_index(drop=True)
# Create trainset and devset
trainset = [dspy.Example(sentence=ex['sentence'], label=str(ex['label'])).with_inputs('sentence') for ex in train_df.to_dict(orient='records')]
devset = [dspy.Example(sentence=ex['sentence'], label=str(ex['label'])).with_inputs('sentence') for ex in val_df.to_dict(orient='records')]Three Steps to Optimization
Using COPRO there will be three steps to optimizing the prompt in the Signaure.
- Baseline evaluation: we will evaluate the nano model against the devset to see how well it does with the Signature we wrote.
- Run COPRO: COPRO will try to optmize the prompt in the Signature.
- Apply the optimized Signature against an error set: using any failed predictions from step one, we will run them again to see if our optimized prompt does any better.
We will log all runs in these steps to LangWatch Experiments so we can see details, costs, get a clear view of how things work in DSPy.
DSPy Configuration
Before we get into the steps we need a DSPy configuration. We will use it in all 3 Steps.
DSPY here is configured with OpenAI’s 4.1-nano model to see what kind of results we can get with the cheapest model.
This is the default model in our configuration. We will use it multiple times. Any DSPy LLM calls we run will use it, unless we specify otherwise.
It is important to keep track of what model is in use when running optimizers.
# Configure DSPy - default model setup to use the cheapest available 4.1-nano from OpenAI
lm = dspy.LM(model="openai/gpt-4.1-nano", api_key=os.environ.get("OPENAI_API_KEY"))
dspy.settings.configure(lm=lm)Step 1 - Baseline Evaluation of 4.1-nano
We first will evaluate the prompt and the 4.1-nano model using the “devset” which is 300 samples so we can get a good sized error set.
This code snip also shows setting up LangWatch to observe the evaluation run.
Note: I had to update the LangWatch DSPy extension to handle logging of DSPy Evaluate runs - that change has been accepted into LangWatch and should be available in the release. If you install the release and its not there yet, you can find the LangWatch DSPy modification here.
Watch out for the Langwatch experiment property in langwatch.dspy.init.
The experiment property sets the name of the experiment you will see in the Langwatch dashboard. Since we will end up logging 3 different major exercises, we want to have a good naming convention to track what each experiment was for.
This experiment is named “grammar-4.1-nano-base-eval”.
# Define evaluation of the test/dev set to see how well the cheapestmodel performs without optimization
evaluator = Evaluate(devset=devset, num_threads=4, display_progress=True, display_table=10, return_outputs=True)
# Initialize Langwatch
try:
langwatch.setup(
api_key=os.environ.get("LANGWATCH_API_KEY"),
endpoint_url=os.environ.get("LANGWATCH_ENDPOINT")
)
# If Langwatch setup fails exit so we do not run llm calls without observability
except Exception as e:
print(f"LangWatch setup failed: {e}")
sys.exit(1)
langwatch.dspy.init(
experiment="grammar-4.1-nano-base-eval",
optimizer=None,
evaluator=evaluator #<-- pass the evaluator for logging to LangWatch-Evaluations
)
# Compile classifier module
classifier = GrammaticalityClassifier()
# Run DSPy evaluation and get the results
score, results = evaluator(classifier, metric=custom_metric)2025-07-22 09:49:41,711 - langwatch.client - INFO - Registering atexit handler to flush tracer provider on exit
2025-07-22 09:49:41,712 - langwatch.client - WARNING - An existing global trace provider was found. LangWatch will not override it automatically, but instead is attaching another span processor and exporter to it. You can disable this warning by setting `ignore_global_tracer_provider_override_warning` to `True`.
[LangWatch] `dspy.evaluate.Evaluate` object detected and patched for live tracking.
[LangWatch] Experiment initialized, run_id: judicious-capuchin-of-thunder
[LangWatch] Open http://localhost:5560/dspy-config-r1AguN/experiments/grammar-41-nano-base-eval?runIds=judicious-capuchin-of-thunder to track your DSPy training session live
Average Metric: 238.00 / 300 (79.3%): 100%|██████████| 300/300 [00:00<00:00, 1854.58it/s]2025/07/22 09:49:42 INFO dspy.evaluate.evaluate: Average Metric: 238 / 300 (79.3%)| sentence | example_label | pred_label | wrapped | |
|---|---|---|---|---|
| 0 | The book what inspired them was very long. | 0 | 0 | ✔️ [True] |
| 1 | This flyer and that flyer differ apart. | 0 | 0 | ✔️ [True] |
| 2 | Anson believed himself to be handsome. | 1 | 1 | ✔️ [True] |
| 3 | John is sad. | 1 | 1 | ✔️ [True] |
| 4 | Any albino tiger has orange fur, marked with black stripes. | 1 | 0 | |
| 5 | The cat were bitten by the dog. | 0 | 0 | ✔️ [True] |
| 6 | I squeaked the door. | 0 | 1 | |
| 7 | Some people consider the dogs dangerous. | 1 | 1 | ✔️ [True] |
| 8 | It is obvious that Pat is lying. | 1 | 1 | ✔️ [True] |
| 9 | Extremely frantically, Anson danced at Trade | 1 | 0 |
... 290 more rows not displayed ...
Evaluation Results
The entire devset has been scored as you can sort of see in the terminal log above. The LLMs are getting so good that we get 79% accuracy out of the box with the lowest model.
The DSPy Evalate terminal log table above is quite nice visually, however its not a longterm record and cannot be referenced easily.
In LangWatch we get the full trace of the Evaluate run. Including the token cost from OpenAI. There is only one “Step” here (shown as the dot on the score graph) because the process did not have any iteration variations.
LangWatch views:
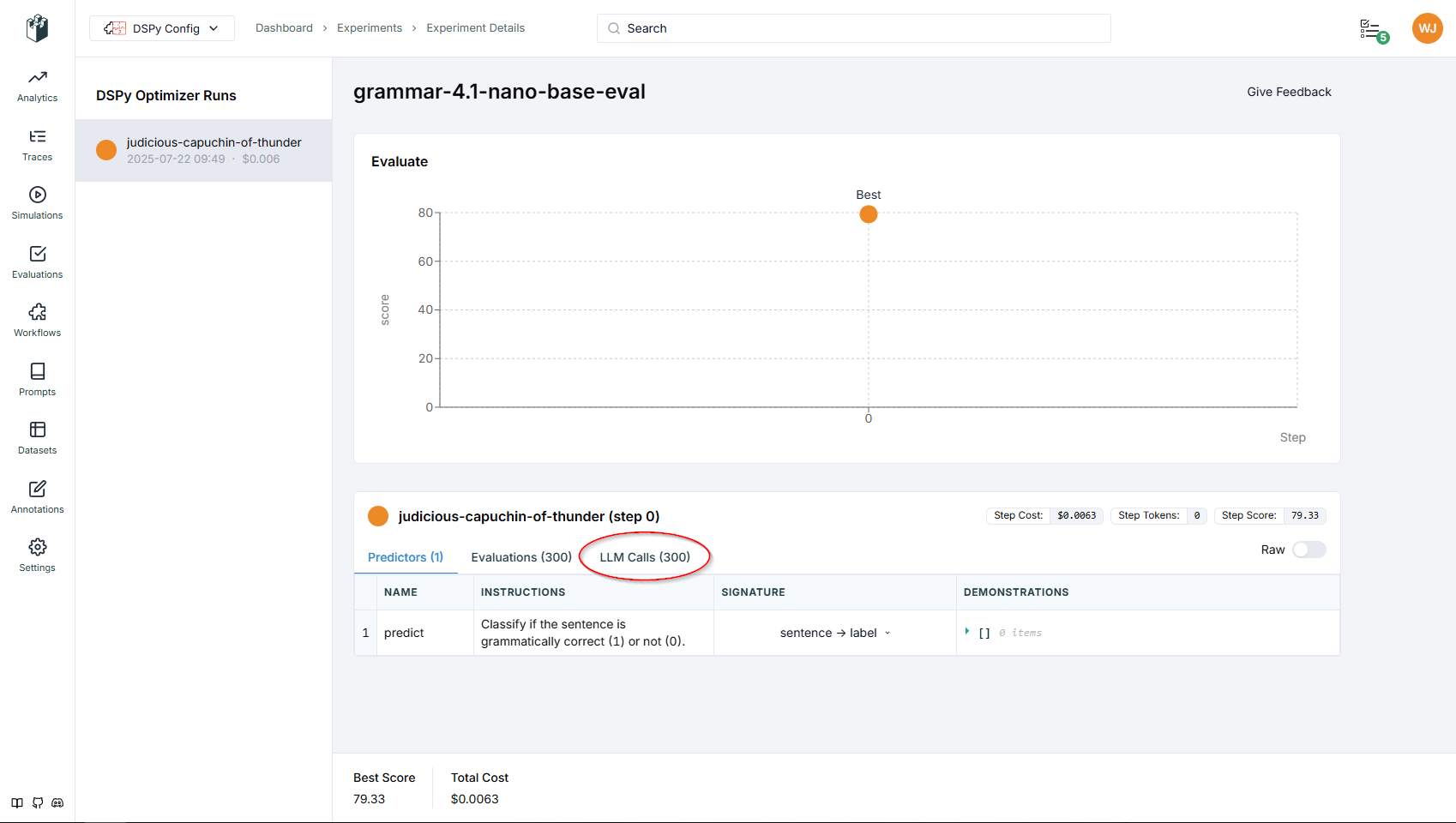
In LangWatch we can see the prompt detail of every individual LLM call on the devset. You can see how DSPy is converting the Signature and Module to a POST to the LLM. Notice we can see it is using the original Singature language.
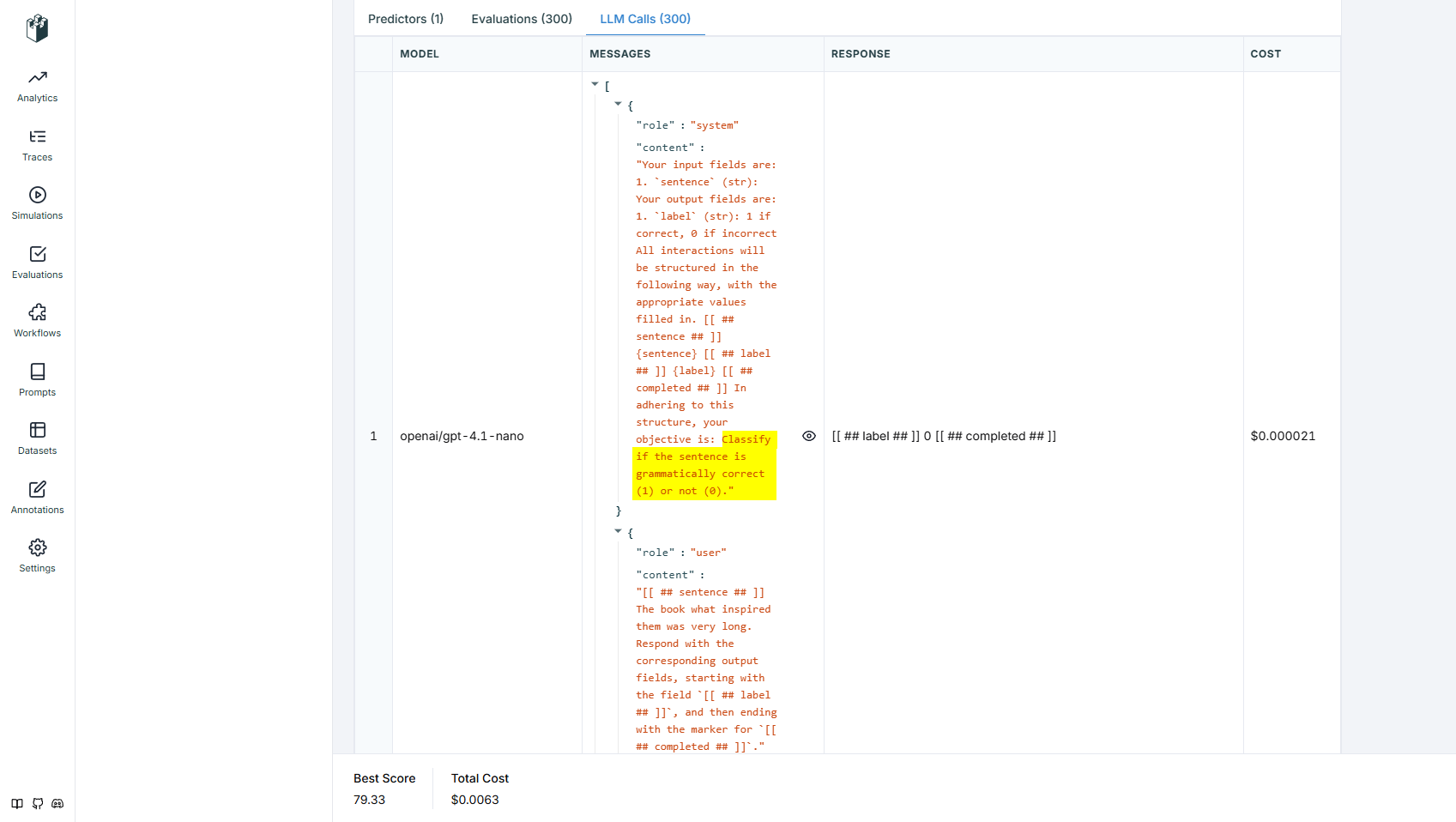
Knowing the nano model is pretty good, I segregate just the failures (mismatches) out. We will use this errors set after optimizing the prompt to see if we can get any improvement on just the hardest sentences.
# Each item in eval_result.results is a tuple: (example, prediction, score)
mismatches = [
{
"sentence": ex.sentence,
"true_label": ex.label,
"predicted_label": pred.label,
"is_correct": metric_result
}
for ex, pred, metric_result in results
if not metric_result
]
# Extract the LLM mismatched items to a CSV file as a set for optimiized analysis
if mismatches:
pd.DataFrame(mismatches).to_csv("cola_grammar_errors.csv", index=False, quoting=csv.QUOTE_ALL)
print(f"Saved {len(mismatches)} error items to cola_grammar_errors.csv")
else:
print("No errors found in evaluation.")Saved 62 error items to cola_grammar_errors.csvStep 2 - Run the COPRO Optimization
Let’s run the COPRO Optimization.
There are few key settings to be aware of that will influence how many LLM calls happen in the optimization.
- trainset size - the number of rows from the dataset up top will be the number of runs per optimization iteration
- breadth - in the optimizer settings below this will be the number of prompt variations that COPRO will generate and test
- depth - this is the number of iterations per prompt COPRO will run.
trainset x breadth x depth = total number of LLM runs.
These can add up to hundreds of LLM requests quickly and may not add much value.
Depending on your use case you will need to experiment to find the best balance for performance vs cost. For this example we have a testset of just 10, and breadth of 3 and depth of 1 to be able to see what is going on with COPRO.
Notice we change the experiment name in the langwatch init.
Also notice we create a new DSPy LM and set it to 4o-mini – this is to use a higher model for prompt variation recommendations that COPRO will request.
Finally the last line, we save the optimization to a JSON file. You can see the modified prompt COPRO selects. This file is important for capturing the optimization and reloading it for long term use with DSPy.
# Configure optimizer
# COPRO generates new prompt va, specify a higher model for this - here we use gpt-4o-mini
prompt_lm = dspy.LM(model="openai/gpt-4o-mini", api_key=os.environ.get("OPENAI_API_KEY"))
optimizer = dspy.COPRO(
prompt_model=prompt_lm,
metric=custom_metric,
breadth=3, #<-- number of prompts to generate
depth=1, #<-- number of iterations (iteration = one prompt variation x tainset size)
init_temperature=1.4
)
# Initialize Langwatch again for the optimizer this time
try:
langwatch.setup(
api_key=os.environ.get("LANGWATCH_API_KEY"),
endpoint_url=os.environ.get("LANGWATCH_ENDPOINT")
)
# If Langwatch setup fails exit so we do not run llm calls without observability
except Exception as e:
print(f"LangWatch setup failed: {e}")
sys.exit(1)
langwatch.dspy.init(experiment="grammar-4.1-nano-copro-train", optimizer=optimizer)
# Compile e.g. run the optimzer
compiled_module = optimizer.compile(GrammaticalityClassifier(), trainset=trainset, eval_kwargs={"num_threads": 4})
# Save the optimized module (GrammaticalityClassifier) to a json file
compiled_module.save("grammatically_optimized.json")2025-07-22 10:21:17,312 - langwatch.client - INFO - Registering atexit handler to flush tracer provider on exit
2025-07-22 10:21:17,313 - langwatch.client - WARNING - An existing global trace provider was found. LangWatch will not override it automatically, but instead is attaching another span processor and exporter to it. You can disable this warning by setting `ignore_global_tracer_provider_override_warning` to `True`.2025/07/22 10:21:17 INFO dspy.teleprompt.copro_optimizer: Iteration Depth: 1/1.
2025/07/22 10:21:17 INFO dspy.teleprompt.copro_optimizer: At Depth 1/1, Evaluating Prompt Candidate #1/3 for Predictor 1 of 1.
2025/07/22 10:21:17 INFO dspy.evaluate.evaluate: Average Metric: 9 / 10 (90.0%)[LangWatch] Experiment initialized, run_id: imperial-cautious-pig [LangWatch] Open http://localhost:5560/dspy-config-r1AguN/experiments/grammar-41-nano-copro-train?runIds=imperial-cautious-pig to track your DSPy training session live [2025-07-22T10:21:17.662141] System message: Your input fields are: 1. `basic_instruction` (str): The initial instructions before optimization Your output fields are: 1. `proposed_instruction` (str): The improved instructions for the language model 2. `proposed_prefix_for_output_field` (str): The string at the end of the prompt, which will help the model start solving the task All interactions will be structured in the following way, with the appropriate values filled in. [[ ## basic_instruction ## ]] {basic_instruction} [[ ## proposed_instruction ## ]] {proposed_instruction} [[ ## proposed_prefix_for_output_field ## ]] {proposed_prefix_for_output_field} [[ ## completed ## ]] In adhering to this structure, your objective is: You are an instruction optimizer for large language models. I will give you a ``signature`` of fields (inputs and outputs) in English. Your task is to propose an instruction that will lead a good language model to perform the task well. Don't be afraid to be creative. User message: [[ ## basic_instruction ## ]] Classify if the sentence is grammatically correct (1) or not (0). Respond with the corresponding output fields, starting with the field `[[ ## proposed_instruction ## ]]`, then `[[ ## proposed_prefix_for_output_field ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`. Response: [[ ## proposed_instruction ## ]] Evaluate the grammatical correctness of the provided sentence. Output "1" if the sentence is grammatically correct and "0" if it is not. Ensure your responses are clear and concise. [[ ## proposed_prefix_for_output_field ## ]] Classify the sentence: [[ ## completed ## ]] (and 1 other completions)
2025/07/22 10:21:18 INFO dspy.teleprompt.copro_optimizer: At Depth 1/1, Evaluating Prompt Candidate #2/3 for Predictor 1 of 1.
2025/07/22 10:21:18 INFO dspy.evaluate.evaluate: Average Metric: 9 / 10 (90.0%)[2025-07-22T10:21:17.662141] System message: Your input fields are: 1. `basic_instruction` (str): The initial instructions before optimization Your output fields are: 1. `proposed_instruction` (str): The improved instructions for the language model 2. `proposed_prefix_for_output_field` (str): The string at the end of the prompt, which will help the model start solving the task All interactions will be structured in the following way, with the appropriate values filled in. [[ ## basic_instruction ## ]] {basic_instruction} [[ ## proposed_instruction ## ]] {proposed_instruction} [[ ## proposed_prefix_for_output_field ## ]] {proposed_prefix_for_output_field} [[ ## completed ## ]] In adhering to this structure, your objective is: You are an instruction optimizer for large language models. I will give you a ``signature`` of fields (inputs and outputs) in English. Your task is to propose an instruction that will lead a good language model to perform the task well. Don't be afraid to be creative. User message: [[ ## basic_instruction ## ]] Classify if the sentence is grammatically correct (1) or not (0). Respond with the corresponding output fields, starting with the field `[[ ## proposed_instruction ## ]]`, then `[[ ## proposed_prefix_for_output_field ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`. Response: [[ ## proposed_instruction ## ]] Evaluate the grammatical correctness of the provided sentence. Output "1" if the sentence is grammatically correct and "0" if it is not. Ensure your responses are clear and concise. [[ ## proposed_prefix_for_output_field ## ]] Classify the sentence: [[ ## completed ## ]] (and 1 other completions)
2025/07/22 10:21:18 INFO dspy.teleprompt.copro_optimizer: At Depth 1/1, Evaluating Prompt Candidate #3/3 for Predictor 1 of 1.
2025/07/22 10:21:18 INFO dspy.evaluate.evaluate: Average Metric: 9 / 10 (90.0%)[2025-07-22T10:21:17.662141] System message: Your input fields are: 1. `basic_instruction` (str): The initial instructions before optimization Your output fields are: 1. `proposed_instruction` (str): The improved instructions for the language model 2. `proposed_prefix_for_output_field` (str): The string at the end of the prompt, which will help the model start solving the task All interactions will be structured in the following way, with the appropriate values filled in. [[ ## basic_instruction ## ]] {basic_instruction} [[ ## proposed_instruction ## ]] {proposed_instruction} [[ ## proposed_prefix_for_output_field ## ]] {proposed_prefix_for_output_field} [[ ## completed ## ]] In adhering to this structure, your objective is: You are an instruction optimizer for large language models. I will give you a ``signature`` of fields (inputs and outputs) in English. Your task is to propose an instruction that will lead a good language model to perform the task well. Don't be afraid to be creative. User message: [[ ## basic_instruction ## ]] Classify if the sentence is grammatically correct (1) or not (0). Respond with the corresponding output fields, starting with the field `[[ ## proposed_instruction ## ]]`, then `[[ ## proposed_prefix_for_output_field ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`. Response: [[ ## proposed_instruction ## ]] Evaluate the grammatical correctness of the provided sentence. Output "1" if the sentence is grammatically correct and "0" if it is not. Ensure your responses are clear and concise. [[ ## proposed_prefix_for_output_field ## ]] Classify the sentence: [[ ## completed ## ]] (and 1 other completions) [2025-07-22T10:21:17.662141] System message: Your input fields are: 1. `basic_instruction` (str): The initial instructions before optimization Your output fields are: 1. `proposed_instruction` (str): The improved instructions for the language model 2. `proposed_prefix_for_output_field` (str): The string at the end of the prompt, which will help the model start solving the task All interactions will be structured in the following way, with the appropriate values filled in. [[ ## basic_instruction ## ]] {basic_instruction} [[ ## proposed_instruction ## ]] {proposed_instruction} [[ ## proposed_prefix_for_output_field ## ]] {proposed_prefix_for_output_field} [[ ## completed ## ]] In adhering to this structure, your objective is: You are an instruction optimizer for large language models. I will give you a ``signature`` of fields (inputs and outputs) in English. Your task is to propose an instruction that will lead a good language model to perform the task well. Don't be afraid to be creative. User message: [[ ## basic_instruction ## ]] Classify if the sentence is grammatically correct (1) or not (0). Respond with the corresponding output fields, starting with the field `[[ ## proposed_instruction ## ]]`, then `[[ ## proposed_prefix_for_output_field ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`. Response: [[ ## proposed_instruction ## ]] Evaluate the grammatical correctness of the provided sentence. Output "1" if the sentence is grammatically correct and "0" if it is not. Ensure your responses are clear and concise. [[ ## proposed_prefix_for_output_field ## ]] Classify the sentence: [[ ## completed ## ]] (and 1 other completions)
That is a lot of output from DSPy to the terminal! 😲
I went to a lot of trouble to leave the output in the notebook and style it so its somewhat readable, in terminal it is very hard to read. We can see what is going on, but we can also see clearer in LangWatch. Lets look at it.
Optimization Results
With a little better prompt language we get some improvement in grammar correctness identification. That’s pretty surprising, althrough the trainset is small at 10 rows.
We can see each variation of 3 in LangWatch. Each is a Step. Clicking the dot on the graph will load the result set in the table below. Notice each step makes 10 LLM calls from the training set plus extras for Optimization requests.
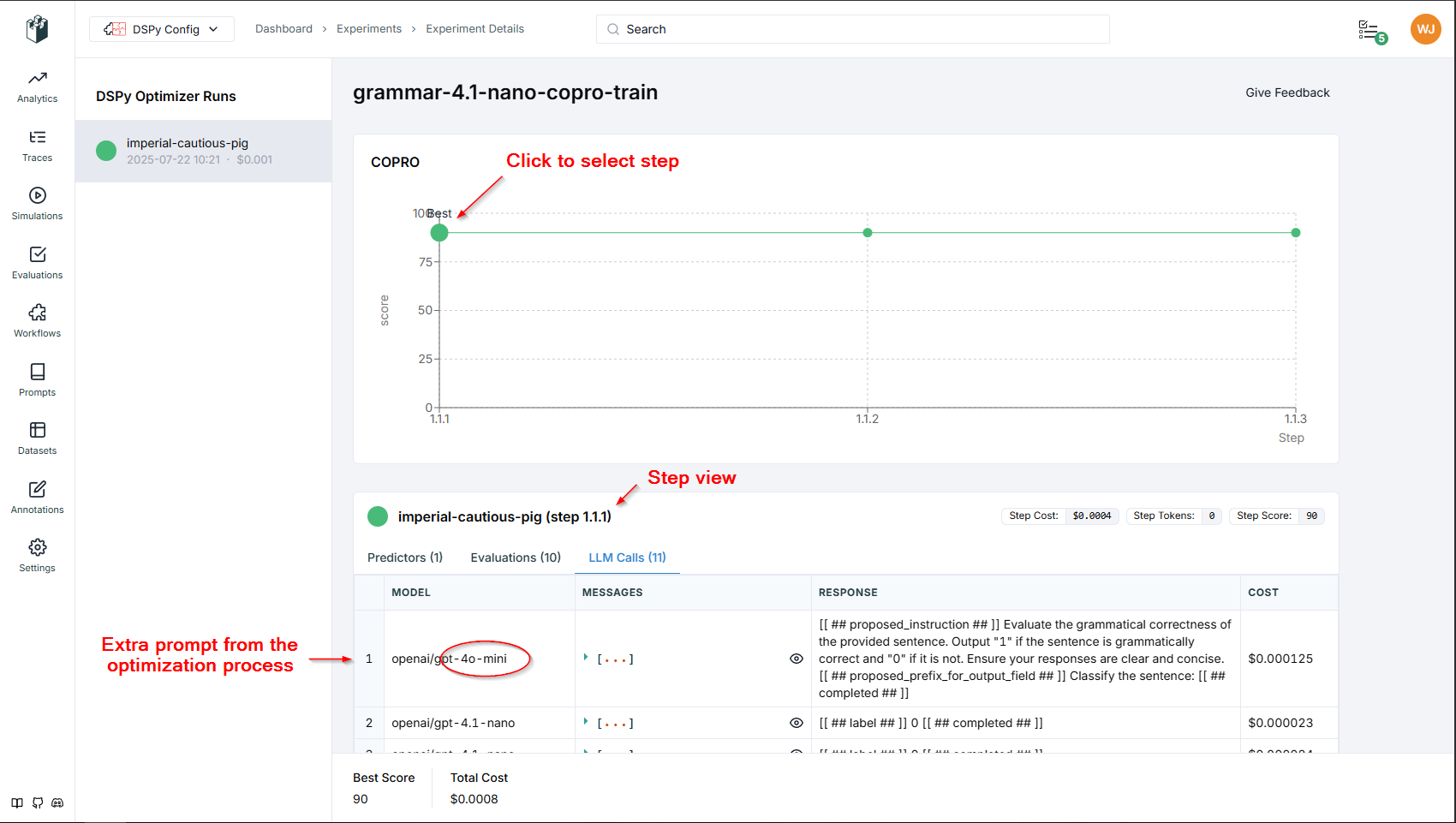
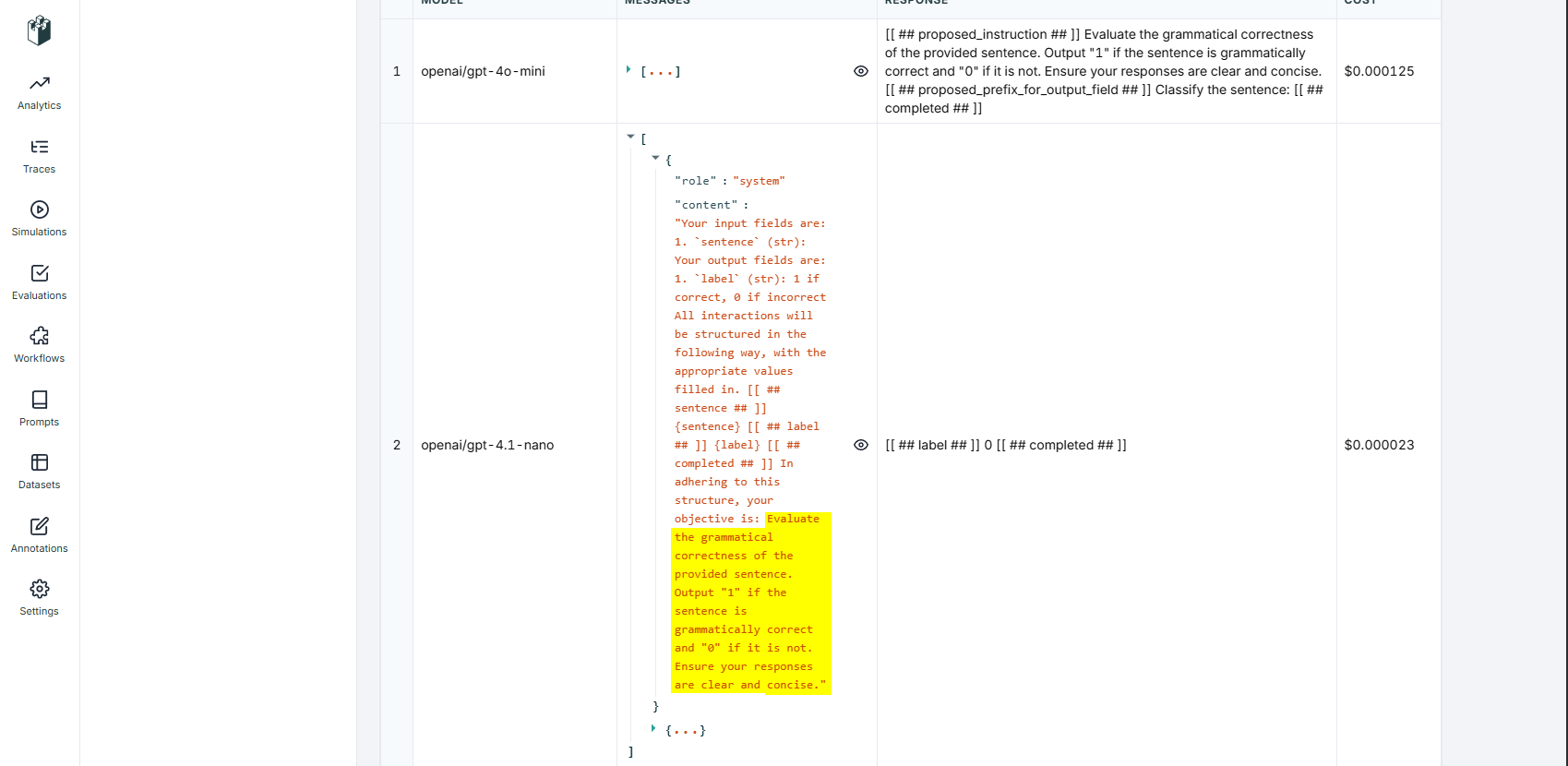
Here is the Copro optimizer asking the LLM for better prompt language. Note how it calls the higher model we set for this purpose.
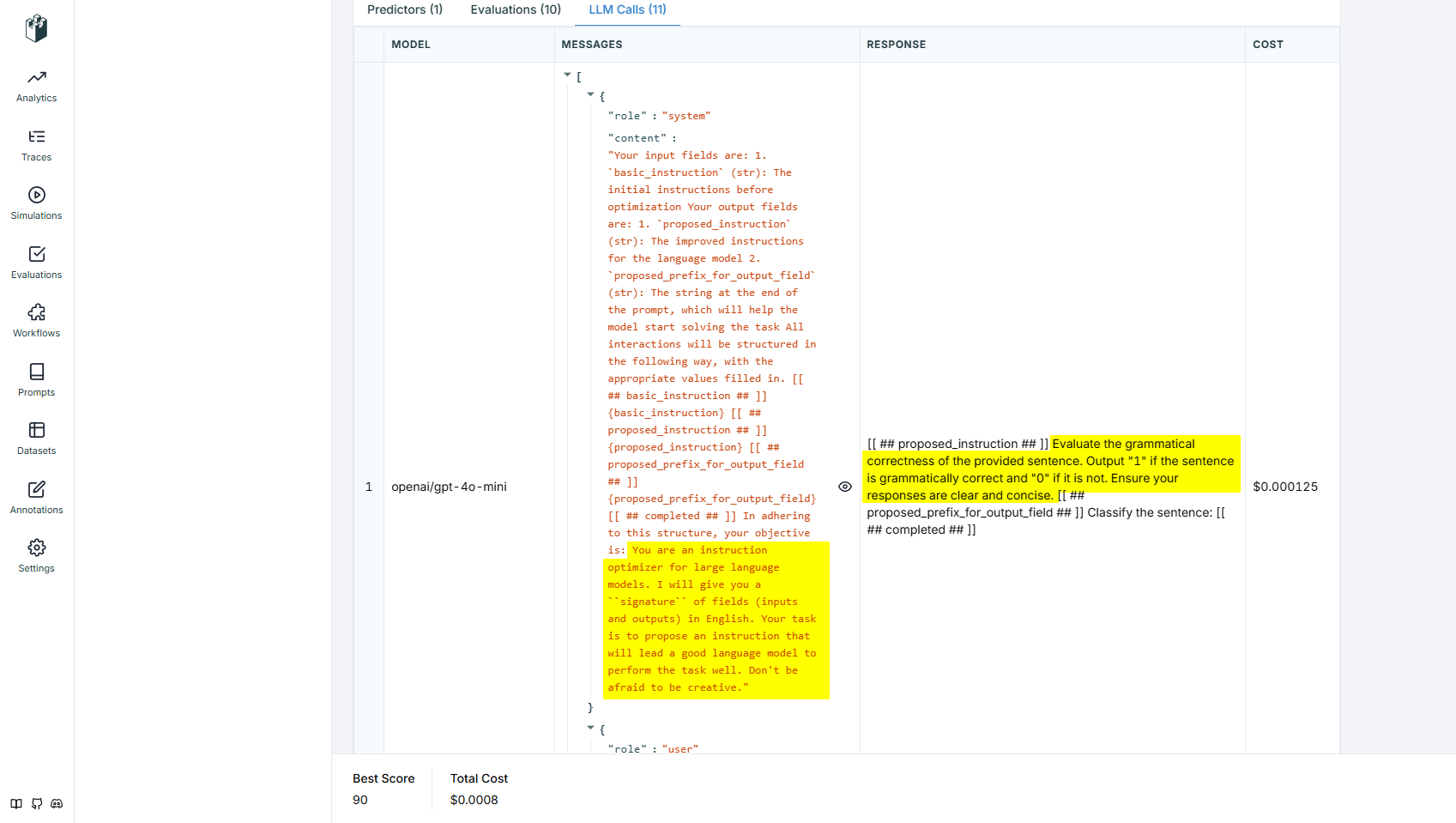
Further in LLM Calls we can see the new prompt sent by DSPy to the LLM to test its effectiveness. Here we see a new prompt variation.
Step 3 - Evaluate the Optimization
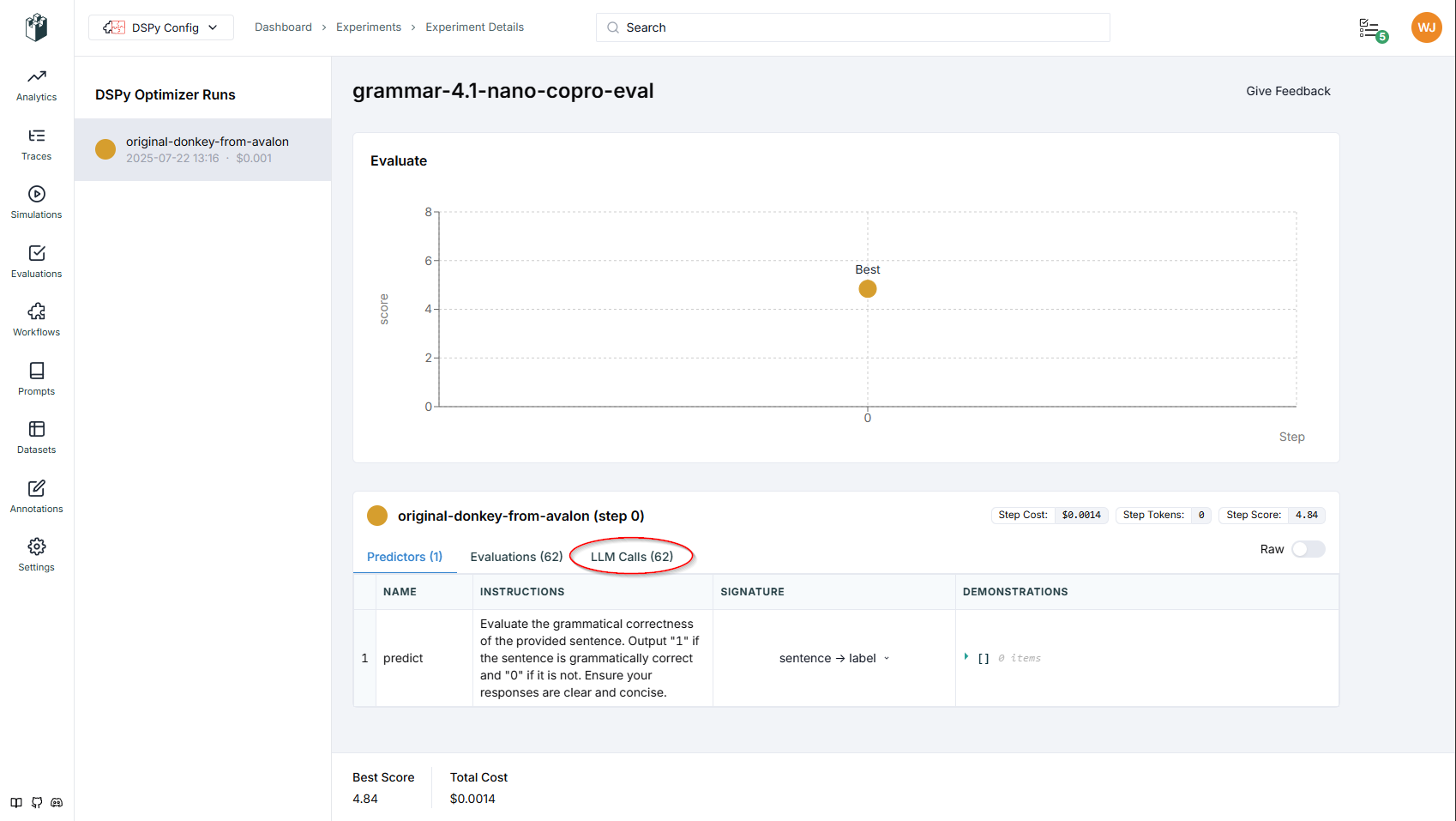
COPRO has already selected the best result for the saved optimization and we had a score of 90% accuracy across the trainset. Lets check it against just the error set from the initial evaluation.
This shows how to reload the optimized model JSON file and setup another evaluation run using the saved error set.
Notice we change the experiment name in the langwatch init a third time, and pass the errorset to Evaluate. The DSPy foundational setup is still 4.1-nano, that never changed.
# Load the optimized classifier state
loaded_classifier = GrammaticalityClassifier() # Recreate the same program with the custom module.
loaded_classifier.load("./grammatically_optimized.json")
# Load the errors dataset
error_df = pd.read_csv("cola_grammar_errors.csv")
# Create a new devset from the mismatches
# (Assuming your columns are: sentence, true_label, predicted_label, is_correct)
errorset = [
dspy.Example(sentence=row['sentence'], label=str(row['true_label'])).with_inputs('sentence')
for _, row in error_df.iterrows()
]
# Evaluate the optimized classifier
optimized_evaluator = Evaluate(devset=errorset, num_threads=1, display_progress=True, display_table=10)
# Initialize Langwatch again
try:
langwatch.setup(
api_key=os.environ.get("LANGWATCH_API_KEY"),
endpoint_url=os.environ.get("LANGWATCH_ENDPOINT")
)
# If Langwatch setup fails exit so we do not run llm calls without observability
except Exception as e:
print(f"LangWatch setup failed: {e}")
sys.exit(1)
langwatch.dspy.init(experiment="grammar-4.1-nano-copro-eval", optimizer=None, evaluator=optimized_evaluator) #<-- pass the evaluator for logging to LangWatch-Evaluations
# Run DSPy evaluation
optimized_evaluator(loaded_classifier, metric=custom_metric)2025-07-22 13:16:09,524 - langwatch.client - INFO - Registering atexit handler to flush tracer provider on exit
2025-07-22 13:16:09,526 - langwatch.client - WARNING - An existing global trace provider was found. LangWatch will not override it automatically, but instead is attaching another span processor and exporter to it. You can disable this warning by setting `ignore_global_tracer_provider_override_warning` to `True`.
[LangWatch] `dspy.evaluate.Evaluate` object detected and patched for live tracking.
[LangWatch] Experiment initialized, run_id: original-donkey-from-avalon
[LangWatch] Open http://localhost:5560/dspy-config-r1AguN/experiments/grammar-41-nano-copro-eval?runIds=original-donkey-from-avalon to track your DSPy training session live
Average Metric: 3.00 / 62 (4.8%): 100%|██████████| 62/62 [00:00<00:00, 725.94it/s] 2025/07/22 13:16:10 INFO dspy.evaluate.evaluate: Average Metric: 3 / 62 (4.8%)| sentence | example_label | pred_label | wrapped | |
|---|---|---|---|---|
| 0 | Any albino tiger has orange fur, marked with black stripes. | 1 | 0 | |
| 1 | I squeaked the door. | 0 | 1 | |
| 2 | Extremely frantically, Anson danced at Trade | 1 | 0 | |
| 3 | She asked was Alison coming to the party. | 1 | 0 | |
| 4 | Either Sam plays the bassoon or Jekyll the oboe. | 1 | 0 | |
| 5 | What did you leave before they did? | 0 | 1 | |
| 6 | Chris handed Bo. | 0 | 1 | |
| 7 | The man who Mary loves and Sally hates computed my tax. | 1 | 0 | |
| 8 | John heard that they criticized themselves. | 0 | 1 | |
| 9 | Over the fire there bubbled a fragrant stew. | 1 | 1 | ✔️ [True] |
... 52 more rows not displayed ...
4.84From the prompt optimization, we get a 4.8% improvement on the hardest grammar examples. That’s not incredible, but it is better than nothing if we’re handling millions of requests. Also the example is to show tooling DSPy and LangWatch more than the best possible optimization.
Again in LangWatch we get our log as before under a separate experiment and done in one Step with 62 LLM calls, one for each in our error set. DSPy selects the most effective prompt from the training run.
Conclusion
Thats it for this basic tutorial on instrumenting COPRO and LangWatch. Hope this has been helpful. You can check out the more advanced DSPy optimizers I’ve also written up on this site, they will be easier to understand once you have been able to follow along on this one.
If you have any questions or suggestions you can reach out to me on Linkedin or on X.